The Acceleration of AI
An Introduction to Neural Networks and GPUs
By Mike Fahrion
CTO, Advantech IIoT Solutions
We have spent most of our lives inside the age of computing, and we’ve grown up with the concept of CPU’s. We understand that higher clock speeds, wider data busses and an increased number of processor cores have enabled today’s CPUs to run increasingly complex software. Among other things, this allows us to watch YouTube videos, write documents and handle large spreadsheets all at the same time.
But, about two decades ago, a new technology began bending the curve, and more recently it has fueled the acceleration of Artificial Intelligence. That new technology was the “Graphical Processing Unit” or “GPU”. In just the last eight years, the advances in GPU power began to deliver on the theoretical promises of Artificial Intelligence. This article will explain what is different and innovative about the GPU as it applies to Artificial Intelligence and Deep Learning.
To appreciate the value of the GPU and understand why this specialized processor class processor has been so influential, we have to look at a different kind of computing, called “Artificial Neural Networks.”
Artificial Neural Networks
Artificial Neural Networks are inspired by the human mind. Among other things, our brain consists of billions of fundamental units called neurons. Neurons are responsible for receiving input from the external world, transforming and relaying the signals, and sending motor commands to our muscles. When triggered by its own input signals, a neuron “fires” to its connected neurons. The creation and tuning of these connections, as well as the strength of the connections, enables our ability to learn.
Looking deeper, those billions of neurons in our brain are organized into parallel columns. A mini-column may contain 100 neurons, further organized into larger hyper-columns, consisting of around 100 million columns. This structure enables our ability to process and act on many inputs, at least seemingly, in parallel. The net result of this large processing structure is the ability to learn by observation and examples rather than by “programming.”
The concept of artificial neural networks in computer science dates back to the 1940s. But only recently have we had the computing power to unleash their potential. Let’s look at how artificial neural networks are constructed.
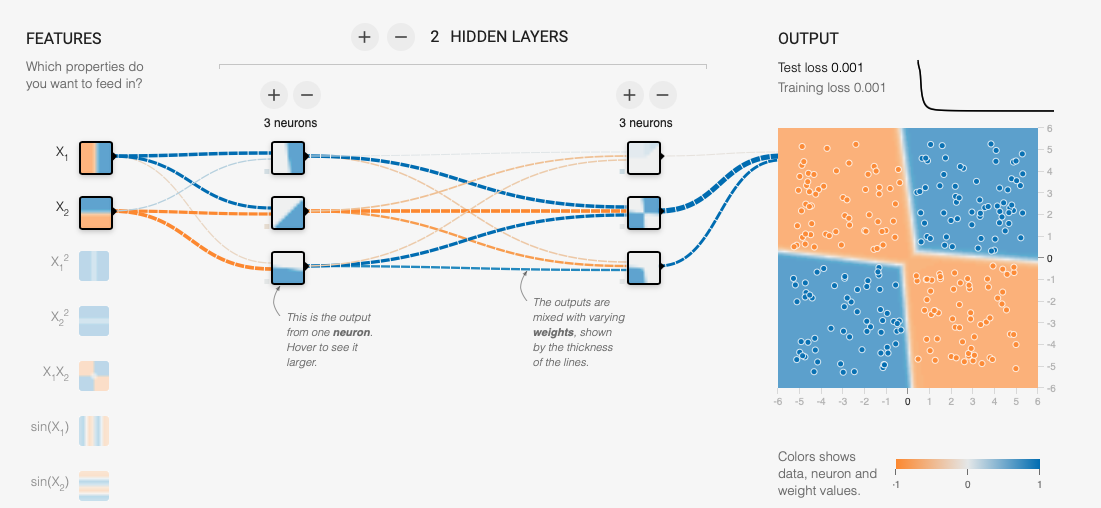
Diagram of a trained neural network using https://playground.tensorflow.org. An excellent educational tool to learn more about artificial neural networks.
Artificial Neural Networks start with the concept of three layers:
The input layer. These nodes perform no calculations, they are simply the input variables, firing their output if the incoming data set matches their conditions.
The “hidden layers” which could be one or many layers where the computational work is done. Each node applies an algorithm to the signals from its input connections to decide whether to fire to its output.
The output layer. If the task of our artificial neural network was to categorize whether an image was a cat or a dog, we would have two output neurons, cat and dog.
That is the basic structure of an artificial neural network. The data set itself, and the number of potential outcomes, will factor into determining the width and depth of this matrix.
Weighting & Propagation
Before we look at how we train this structure to perform useful tasks, there are three concepts we need to examine.
First is the concept of “weighted connections”. Each of the nodes in each of the layers is connected to each node in the next layer. The strength, or relevance of those connections is given a weighting factor. This factor will determine the influence of that node as an input to the next algorithm. Note that, in the figure above, the line thickness represents the weighting in the trained network. Prior to the training, all weightings are equal.
Next is the concept of “forward propagation.” This is the process of getting an output from the network for any given input by traveling through those weighted connections.
Finally, we have “reverse propagation.” This function enables the artificial neural network to “learn.” In reverse propagation, the network compares training data to the output produced by the network. By propagating any “error” backwards into the network, it calculates how much each connection contributed to the error and applies a correction factor to the weighting of that connection. By iterating this process through a set of labeled training data, the network will optimize itself such that it produces the most correct result possible for any set of inputs.
With that fundamental knowledge, we can examine how an artificial neural network is “trained.”
Learn, Repeat, Evolve
Let’s assume we are training our network to recognize if an image is an X or an O. Our first task is to configure our artificial neural network, deciding how many input nodes, how many hidden layers to use, how many nodes in each hidden layer, and how many output nodes. These configuration decisions are based on math, intuition and experimentation.
The network then examines its first training data, images already labeled as a known “X” or “O.” Initially, all connections are weighted equally. The data forward propagates through the network, producing a random result. The network then compares that output with the known correct answer provided by the labeled data set. Errors are reverse propagated back through the network. Connections that contributed to the error are weakened. Connection scores that contributed to correct outcomes are strengthened. Using this iterative process, the network trains itself, creating the artificial neural network model required to correctly classify the data set. That completed “model” can then be deployed and used to “infer” correct outcomes with raw, unlabeled data.
Armed with that knowledge of real and artificial neural networks, let’s examine the Graphical Processing Unit, or GPU.
Brain Power for AI
Neural networks are a parallel processing paradigm. The more simultaneous calculations that can be done, the faster a network can be “trained” and, the faster a trained network can process new unlabeled data. The calculations themselves are fairly simple, so we’d like a processor architecture capable of performing as many simple mathematical calculations as quickly as possible. Traditional CPUs are built to be general purpose computing tools, able to be programmed to perform a wide variety of functions, generally in a sequential fashion. In comparison, a GPU is a purpose-built type of processing unit built to perform a narrower set of functions in a massively parallel manner.
Today’s CPU have a small number of highly complex cores, each capable of a wide variety of complex operations. In comparison, a GPU will have hundreds or thousands of small cores optimized for a limited set of mathematical operations. This structure is ideal for the intensive, high throughput, parallel processing needed to train an artificial neural network, as well as to quickly execute a trained model against new data sets.
Images are inherently a large data set. When GPUs first entered the scene, their domain was gaming and graphics. That same GPU architecture has proven to be very effective for artificial neural networks. Applying GPUs to artificial neural networks has accelerated development and deployment of AI deep learning applications, where complex algorithms aren’t programmed, the network is “trained.”
Advantech, as the leading manufacturer of industrial computing platforms, offers a wide array of both CPU and GPU based industrial PCs designed specifically for rugged environments.